【Trouble shooting hack】Web サービスにおけるシステム障害の原因特定アプローチ
当記事はユアマイスター アドベントカレンダー 2022の 12 日目の記事です。
想定読者
- 自社の事業で Web サービス開発をしているエンジニアの方
- Web サービス運用でシステム障害発生時に迅速に原因を特定したいエンジニアの方
当記事で言及すること
システム障害発生の原因を特定するアプローチ
当記事で言及しないこと
- 障害レベル策定
- 関係各所への共有
- 障害検知体制
- 障害復旧方法(暫定対応・根本対応)
当記事で取り上げる「Web サービスにおけるシステム障害」の定義
まずは前提を揃えます。
Web サービスにおけるシステム障害は「何らかの原因でその Web サービスが正常に動作しなくなった状態」を指します。この記事でフォーカスしたいのは、特定のリクエストにおいて主に HTTP ステータスコードの500 番台(サーバーエラー)がレスポンスで返却されるようなケースです。
システム障害の原因の大まかな区分
概論から入ります。イメージしやすいよう、Web サービスのシステム構成が AWS を基盤としたシンプルな構成であると仮定します:
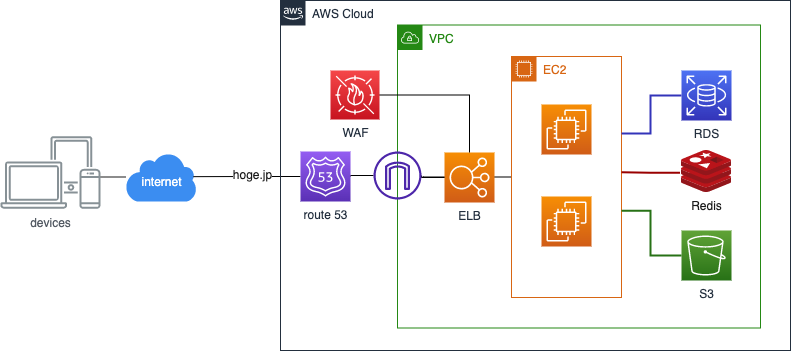
Web ブラウザを介して hoge.jp にアクセスした訪問者はリクエストが上図から見て左 → 右へ流れ、レスポンスは右 → 左へ流れていきます。この構成に従うと、システム障害の発生原因はおおよそ下記いずれかになります:
- DNS 設定
- ロードバランサー・WAF 設定
- Web サーバー・AP サーバー設定・負荷
- ソースコード内のバグ等
- OS 設定
- データベース設定・構成・負荷
- ネットワーク設定
速やかに原因を特定するには、システム構成の全体図を日頃から把握しておくのが大事です。以下、上記 7 つの原因を使いながら解説します。
どんな時に発生したシステム障害かで、疑う原因を絞り込む
過去に Web サービスを実運用してみて、システム障害が発生することの多かったケースとそれに該当しやすい原因を列挙します。
CASE1: 新機能リリース後
- Web サーバー・AP サーバー設定・負荷
- ソースコード内のバグ等
- データベース設定・構成・負荷
CASE2: 各種バージョンアップ対応後
- Web サーバー・AP サーバー設定・負荷
- ソースコード内のバグ等
- データベース設定・構成・負荷
CASE3: システム構成変更後(サーバーリプレース含む)
- DNS 設定
- ロードバランサー・WAF 設定
- Web サーバー・AP サーバー設定・負荷
- データベース設定・構成・負荷
- OS 設定
- ネットワーク設定
CASE4: テレビ番組で Web サービスが紹介されている最中
- Web サーバー・AP サーバー設定・負荷
- データベース設定・構成・負荷
※各種サーバーのスペックが足りないケースもありえます
CASE5: BOT が Web サービスへ大量にアクセスしている最中
- ロードバランサー・WAF 設定
- ソースコード内のバグ等
- データベース設定・構成・負荷
CASE1~5 を眺めていただくと分かるように、システム障害発生直後からすぐに原因が特定できるケースは稀で、大抵は 1 つのシステム障害に対して複数の原因が考えられることが多いです。それでもおおよその勘所があると数ある原因をいくらか絞り込んで調査初動を早めることができるので、押さえておくと良いでしょう。
原因を調査するにあたり、優先順位を決める方法
まずはアラートやモニタリング情報を把握するところから始まります。
AWS 等のクラウドサービスを利用していると CPU 負荷やメモリ使用量、各種ログをモニタリングできる機能が大抵付随するため、基本的にはクラウドサービス内でアラートやモニタリング情報を確認することが多いかと思われます。あるいは自社で導入している監視サービスのアラートやモニタリング情報、他にもサーバーへ ssh してログを確認することもあります。
これらを駆使し、システム障害発生の原因になっている可能性の高い候補から順に調査していきます。
原因特定のための調査例(データベース設定・構成・負荷)
各論に入ります。本来なら 7 つのシステム障害発生原因毎に書き出したいのですが記事ボリュームが大きくなりすぎるため、今回は頻出しやすい データベース設定・構成・負荷 に絞り解説します。
データベースにおけるシステム障害の代表的な例は CPU 負荷が 100%に達する ことで発生するもので、大抵はアラートやモニタリング情報で確認可能です。以下では CPU 負荷が 100%に達する原因をどのように特定するか見ていきます。
CPU 負荷が 100%に達する原因
CPU 負荷が高い時は、付随してモニタリングに変化が現れやすい情報があります。代表的なものが
- データベース接続数の増加
- 書き込み IOPS 数の増加
- スロークエリの増加
です。まずは上記 3 つのうちどれに該当しているかを調べてください。
1. データベース接続数の増加の場合
Web サーバー・AP サーバーが大量のリクエストを捌くために展開したプロセス数に比例して増えることが多く、該当しやすいシステム障害発生ケースは「テレビ番組で Web サービスが紹介されている最中」となります。この時は普段の数倍のアクセスが一気に流入することもあり、データベース接続数が普段よりも桁 1~2 つくらい増えます。
2. 書き込み IOPS 数の増加の場合
大量のデータを一度にデータベースへ書き込むようなバッチ処理時によく見受けられます。何もせずに急増することは少なく、「新機能リリース後」で新しいバッチもしくは既存バッチのロジック変更をリリースした時に見受けられます。
3. スロークエリの増加の場合
ソースコードプログラムからデータベースへ投げるクエリにインデックスが効きづらいものがある場合によく見受けられます。こちらも「新機能リリース後」に発生しやすいです。普段からスロークエリログを吐き出さない設定にしている場合、仮にデータベースが MySQL であれば
show processlist;
show full processlist;
いずれかのコマンドをインターバル設けながら複数回実行してスロークエリの発生を確認しつつ、どのクエリが時間かかっているのかを特定するのも 1 つの方法です。
まとめ
- システム構成の全体図を把握しておくと、障害が発生しうるポイントを把握しやすくなります
- ケースバイケースで何が原因となりうるかを押さえておくと、調査の初動が早くなります
- 調査の優先順位はアラートやモニタリングを確認して決めましょう
- データベースの障害で CPU が 100%になる場合、付随してモニタリング情報に変化が現れることが多いのでそちらも確認しましょう